

Seit einigen Jahren verwende ich bereits Zabbix für das Monitoring meinem Netzwerk. Immer wieder kommt es vor, das ich mir z.B. die Auslastung einer VM oder eines Netzwerk-Interfaces über einen Tag anzeigen lassen möchte.
Das funktioniert an sich zwar schon, nur mit der Anzahl an Datenpunkten und der Anzahl von Hosts wird Zabbix mit der Zeit sehr Ressourcen-Lastig auf der SQL-Datenbank und das berechnen der Graphen dauerte teilweise mehrere Minuten. Die Worker für die Bereinigung der History-Tabelle waren immer wieder für viele Minuten völlig ausgelastet, was nicht gerade die Performance des Servers verbesserte.
Seit einiger Zeit bringt Zabbix auch die (experimentelle) Unterstützung für Elasticsearch mit und speichert und liest die Daten dann von dort um das SQL-Backend zu entlasten. Es existiert zwar eine Seite mit einigen Infos welche Konfigurationsschritte erklären, aber diese haben bei mir nicht wirklich zu einer funktionierenden Konfiguration geführt:
5 Elasticsearch setup [Zabbix Documentation 5.4]
Es waren einige zusätzliche Schritte notwendig, damit Zabbix alle Werte in Elasticsearch speichern und auch wieder korrekt auslesen kann, damit hier wieder Graphen erstellt werden können.
Folgende Umgebungen werden benötigt:
- Ein Zabbix-Server (in diesem Beispiel in Version 5.4 auf FreeBSD)
- Eine Elasticsearch-Instanz (in diesem Beispiel mit Kibana in Version 7.12.1 für eine einfachere Konfiguration), auch ELK-Stack genannt auf FreeBSD
In diesem Beispiel laufen die beiden Server nicht auf dem selben Host, allerdings ist eine Trennung nicht unbedingt notwendig.
1. Die Funktion für die Nutzung von Elasticsearch muss in der Zabbix-Server-Konfiguration (/usr/local/etc/zabbix52/zabbix_server.conf) folgende Zeilen auskommentiert bzw. hinzugefügt werden:
HistoryStorageURL=http://<Elasticsearch-Host>:9200
HistoryStorageTypes=uint,dbl,str,log,text
HistoryStorageDateIndex=1In der Datei "/usr/local/www/zabbix52/conf/zabbix.conf.php" müssen folgende Zeilen eingefügt werden:
Am Anfang der Datei muss (falls noch nicht vorhanden) direkt nach den beiden ersten 2 Zeilen
<?php
// Zabbix GUI configuration file.Die Zeile
global $DB, $HISTORY;eingefügt werden. Die SQL-Variablen für die Datenbankverbindung verbleiben unverändert.
Nun gibt es im unteren Bereich der Konfigurationsdatei den Bereich für Elasticsearch. Hier ersetzen wir die vorhandenen auskommentierten Zeilen mit folgenden Zeilen:
// Uncomment this block only if you are using Elasticsearch.
// Elasticsearch url (can be string if same url is used for all types).
$HISTORY['url'] = 'http://<Elasticsearch-Host>:9200';
// Value types stored in Elasticsearch.
$HISTORY['types'] = ['str', 'text', 'log', 'dbl', 'uint'];Hiermit wird dem Webinterface mitgeteilt, nun die Host-Historie nicht mehr aus der SQL-Datenbank zu laden, sondern direkt aus Elasticsearch. Die Änderungen abspeichern, aber den nginx-Webserver noch nicht neu starten.
Nun müssen einige Vorbereitungen auf der Elasticsearch-Instanz getroffen werden. Wie bereits schon ausgeführt, wird mit der jetztigen Konfiguration zwar der Export der Historie funktionieren, aber Zabbix wird nicht in der Lage sein, die Daten wieder korrekt auf der Weboberfläche ausgeben zu können.
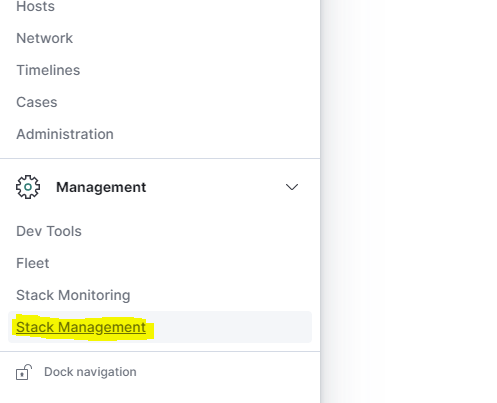
Wir öffnen also Kibana auf unserer gewünschten Instanz und wählen dort im Menü auf der linken Seite unten "Stack Management" aus:
Nun klicken wir oben links auf "Ingest Node Pipelines":
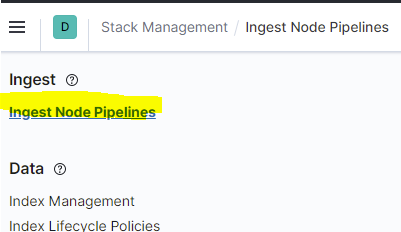
Hintergrund: "Ingest Node Pipelines" ermöglichen es uns die Daten welche Zabbix in die Instanz ablädt nachzubearbeiten. Dies ist notwendig, da Zabbix intern andere Datentypen als Elasticsearch nutzt und die automatische Konvertierung bzw. Erkennung der Datentypen durch Elastic leider nicht immer fehlerfrei funktioniert.
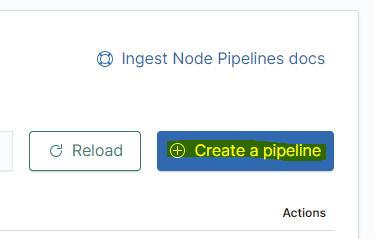
Nun klicken wir oben rechts auf die Schaltfläche "Create a pipeline" (Die nächsten Schritte werden für JEDEN Datentyp von Zabbix wiederholt werden):
Hier wird nun für jeden Datentyp nun die Pipeline angelegt, welcher das Datumsformat des Zabbix-Servers in einem Timestamp für Elasticsearch konvertiert (@timestamp) und dann der Wert "value" auf den Typ "double" konvertiert.
Das sieht dann fertig so aus:
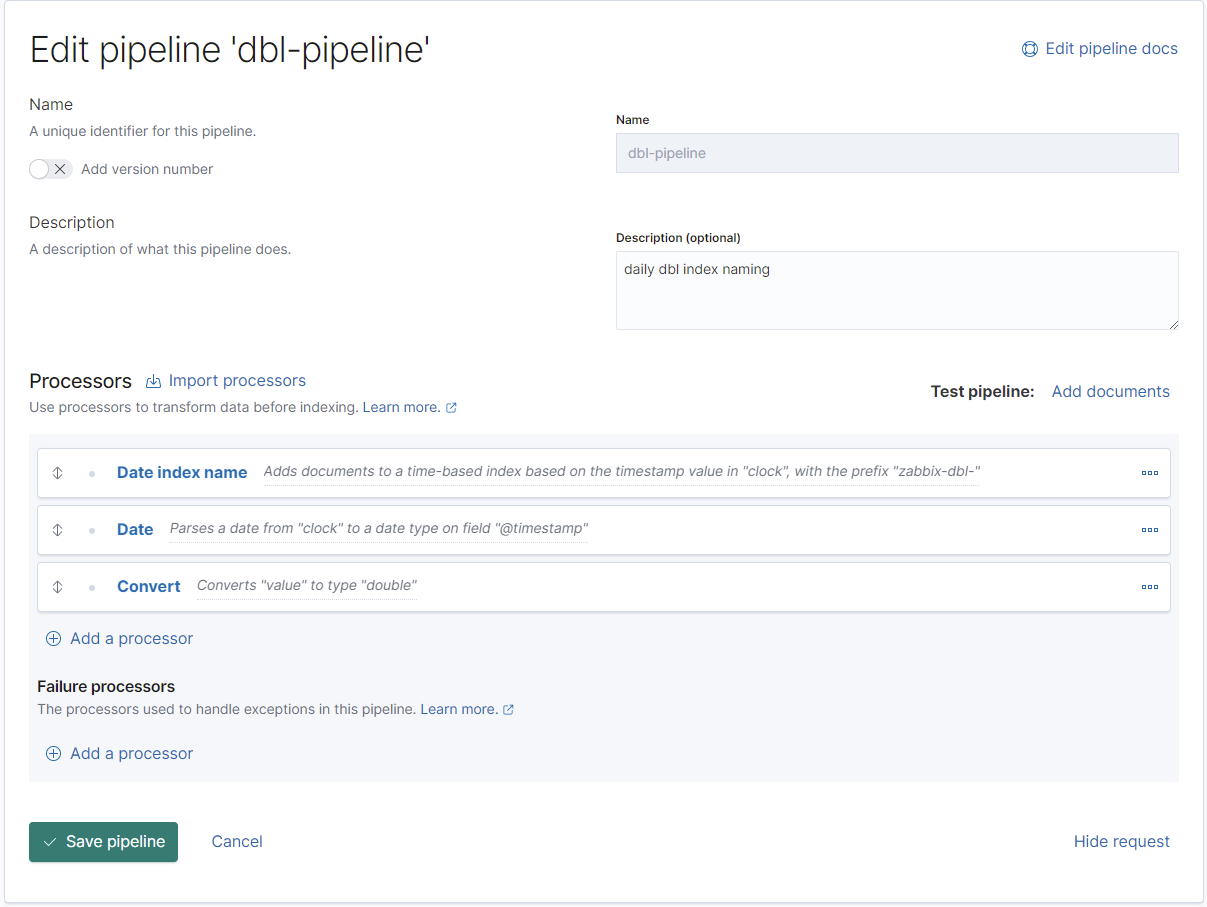
REST-Profis können auch einfach das folgende mittels CURL an den Elastic-Stack senden:
PUT _ingest/pipeline/dbl-pipeline
{
"description": "daily dbl index naming",
"processors": [
{
"date_index_name": {
"field": "clock",
"date_rounding": "d",
"index_name_prefix": "zabbix-dbl-",
"date_formats": [
"UNIX"
]
}
},
{
"date": {
"field": "clock",
"formats": [
"UNIX"
]
}
},
{
"convert": {
"field": "value",
"type": "double"
}
}
]
}Nun das selbe Spiel mit der Log-Pipeline (ohne Typ-Konvertierung):
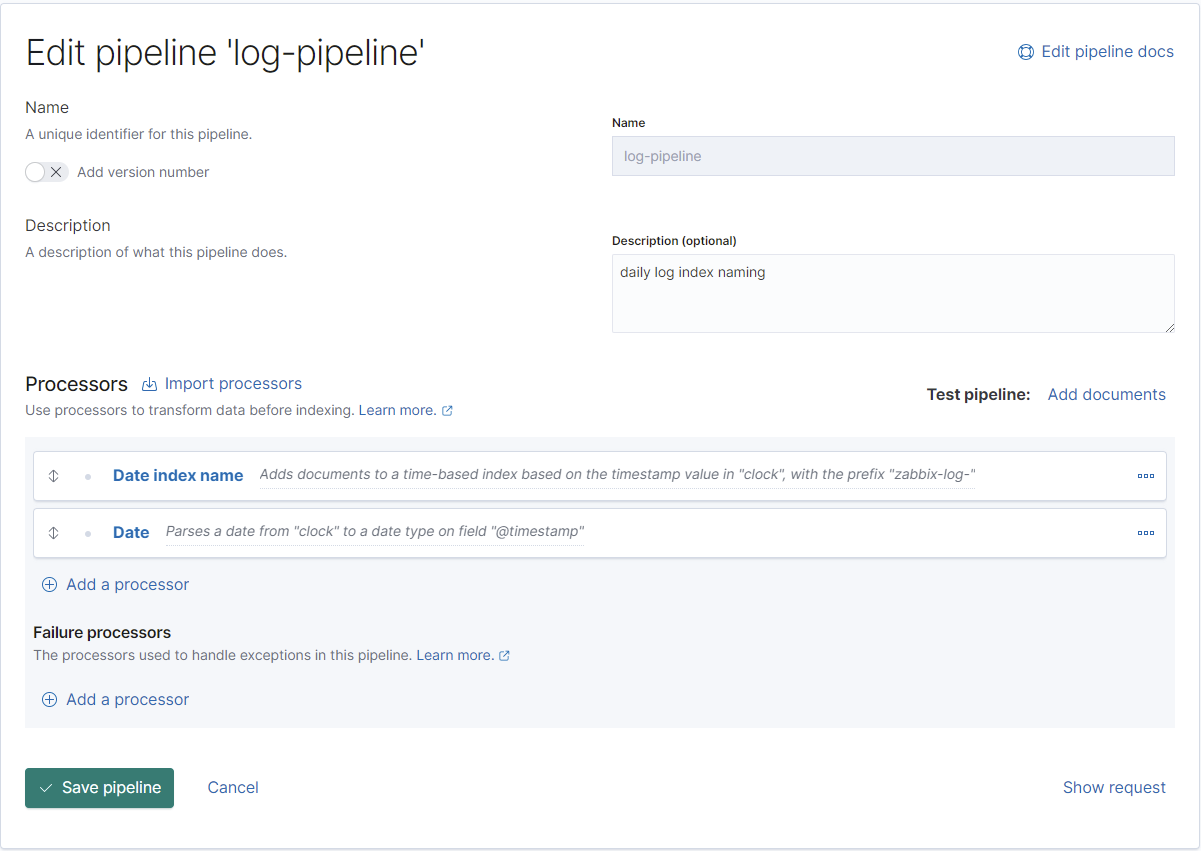
REST:
PUT _ingest/pipeline/log-pipeline
{
"description": "daily log index naming",
"processors": [
{
"date_index_name": {
"field": "clock",
"date_rounding": "d",
"index_name_prefix": "zabbix-log-",
"date_formats": [
"UNIX"
]
}
},
{
"date": {
"field": "clock",
"formats": [
"UNIX"
]
}
}
]
}Beim Typ "str" wird auch keinerlei Konvertierung durchgeführt (Elasticsearch führt standardmäßig alle nicht identifizierbaren Felder als Text):
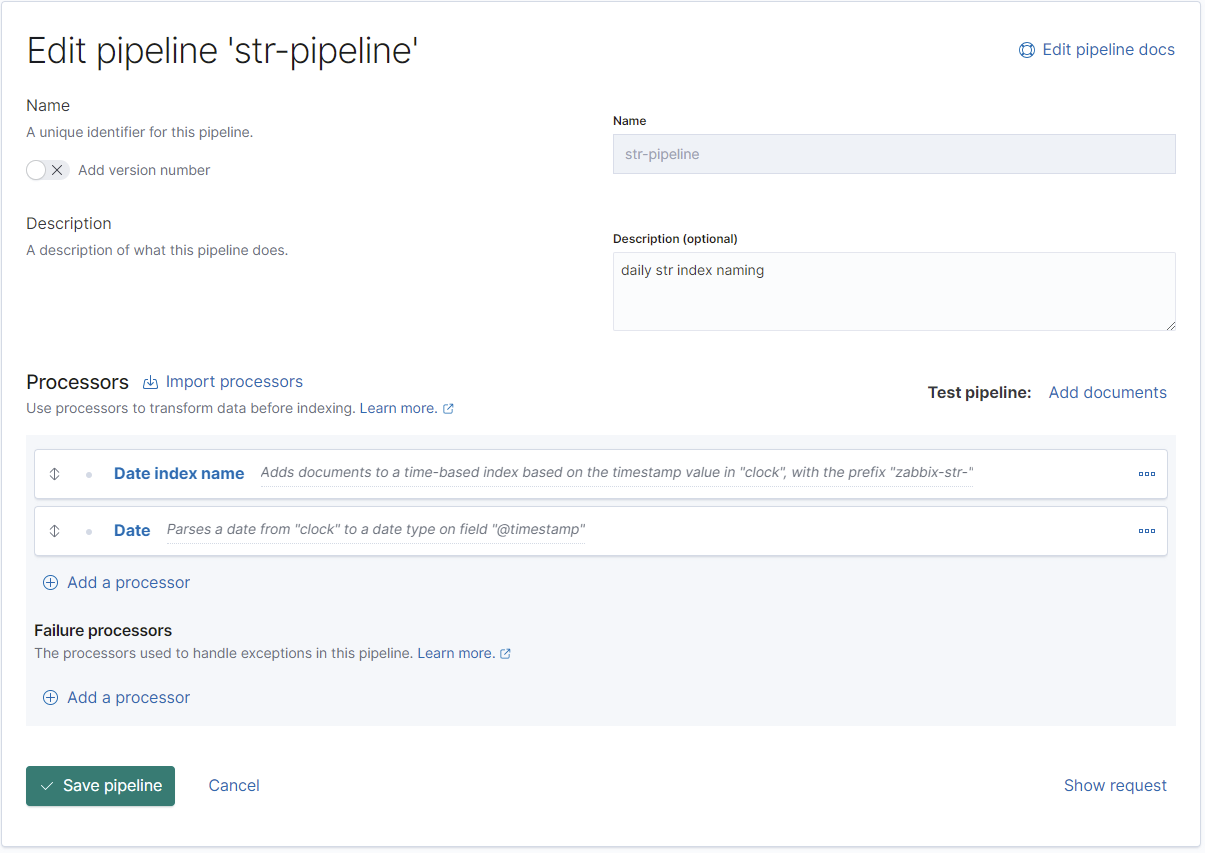
REST:
PUT _ingest/pipeline/str-pipeline
{
"description": "daily str index naming",
"processors": [
{
"date_index_name": {
"field": "clock",
"date_rounding": "d",
"index_name_prefix": "zabbix-str-",
"date_formats": [
"UNIX"
]
}
},
{
"date": {
"field": "clock",
"formats": [
"UNIX"
]
}
}
]
}Beim "Text" Datentyp das selbe Spiel:
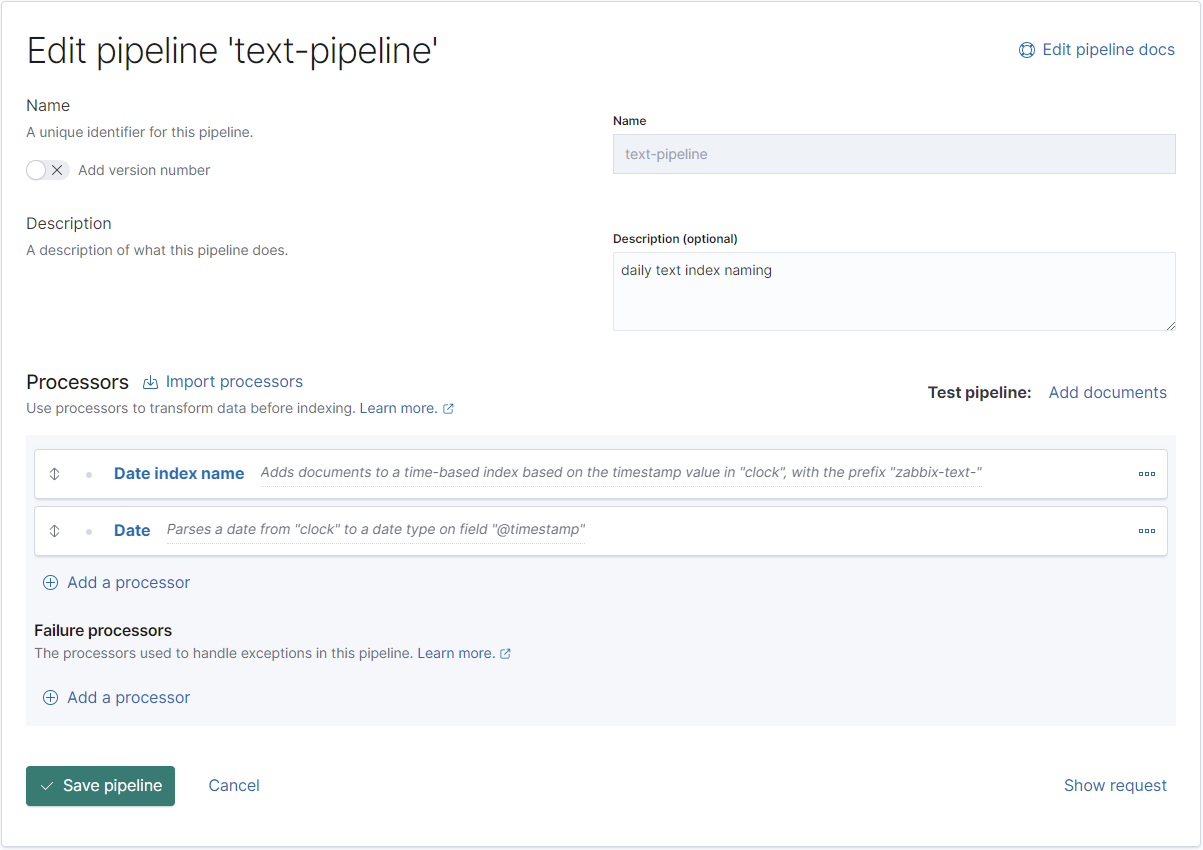
REST:
PUT _ingest/pipeline/text-pipeline
{
"description": "daily text index naming",
"processors": [
{
"date_index_name": {
"field": "clock",
"date_rounding": "d",
"index_name_prefix": "zabbix-text-",
"date_formats": [
"UNIX"
]
}
},
{
"date": {
"field": "clock",
"formats": [
"UNIX"
]
}
}
]
}Jetzt wird es spannend (und das ist auch das wirklich problematische bei dem Import der Daten vom Zabbix-Server nach Elasticsearch): Bei den Ganzzahlen reicht NICHT der Integer-Typ von Elasticsearch aus, sonder es muss auf "Long" konvertiert werden. Das böse dabei: Je nachdem welche Werte Zabbix als erstes in den Elasticsearch-Instanz exportiert, kann der Wertebereich noch passen, doch irgendwann läuft es beim Import auf einen Fehler und auf der Weboberfläche des Zabbix-Servers werden keine Werte mehr angezeigt, da Elasticsearch die Werte nicht im Index abbilden konnte.
Hier muss also eine Konvertierung des Wertes "value" in "long" erfolgen:
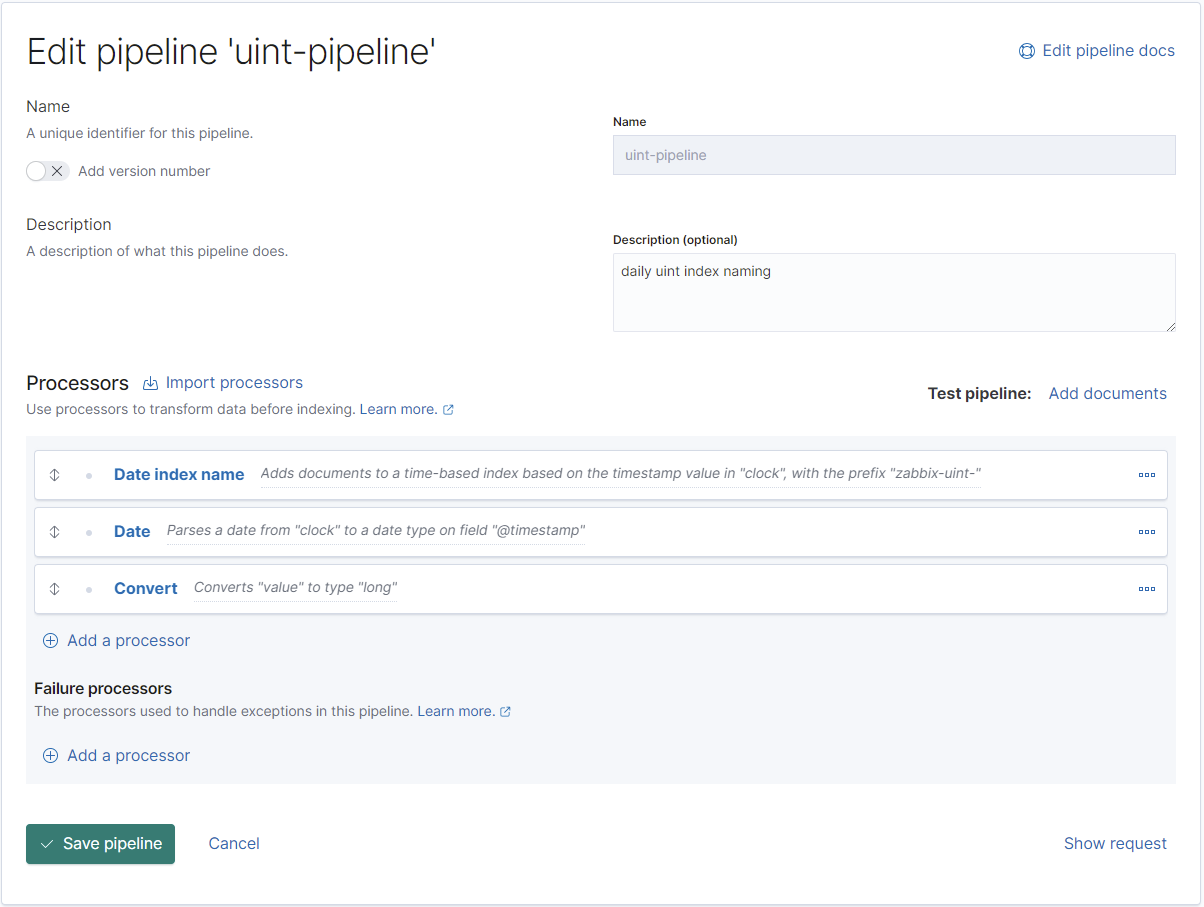
REST:
PUT _ingest/pipeline/uint-pipeline
{
"description": "daily uint index naming",
"processors": [
{
"date_index_name": {
"field": "clock",
"date_rounding": "d",
"index_name_prefix": "zabbix-uint-",
"date_formats": [
"UNIX"
]
}
},
{
"date": {
"field": "clock",
"formats": [
"UNIX"
]
}
},
{
"convert": {
"field": "value",
"type": "long"
}
}
]
}Nach dem Erstellen der 5 Pipelines müssten nun diese in Kibana angezeigt werden:
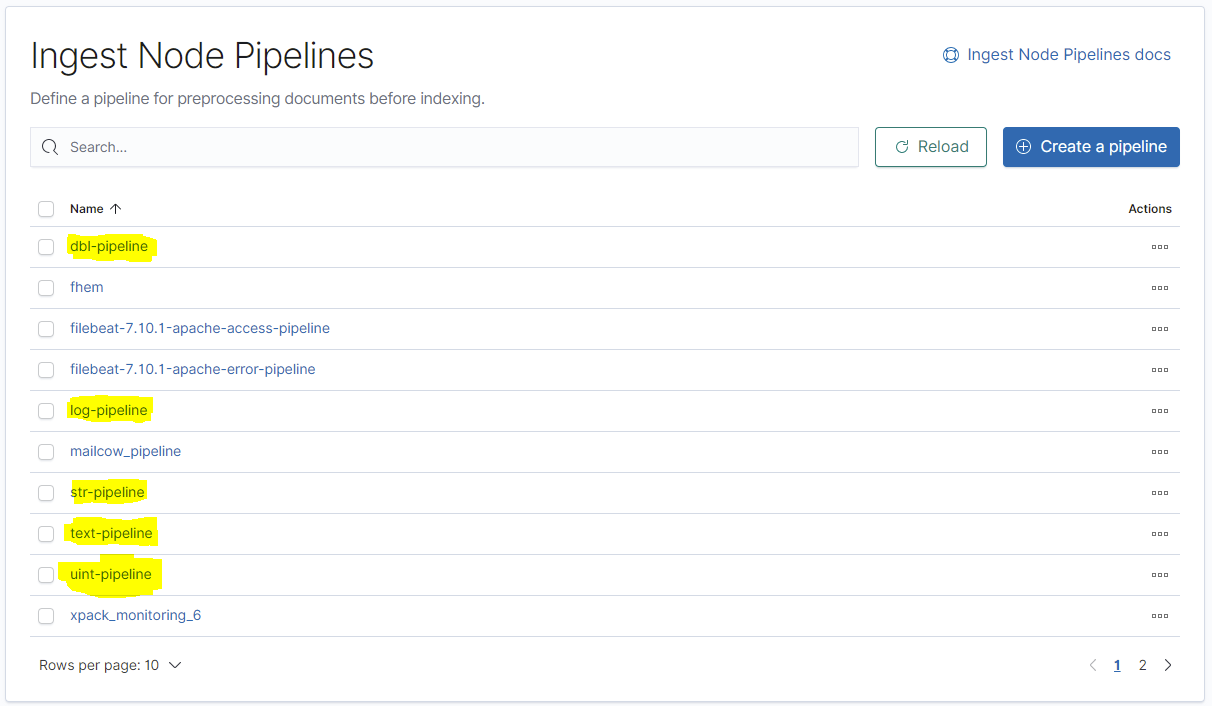
Nun klicken wir links im Menü auf "Index Management":
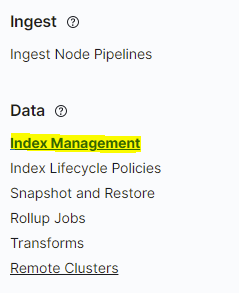
Im Index Management klicken wir oben auf den Reiter "Index Templates" und danach klicken wir auf die Schaltfläche "Create legacy template":
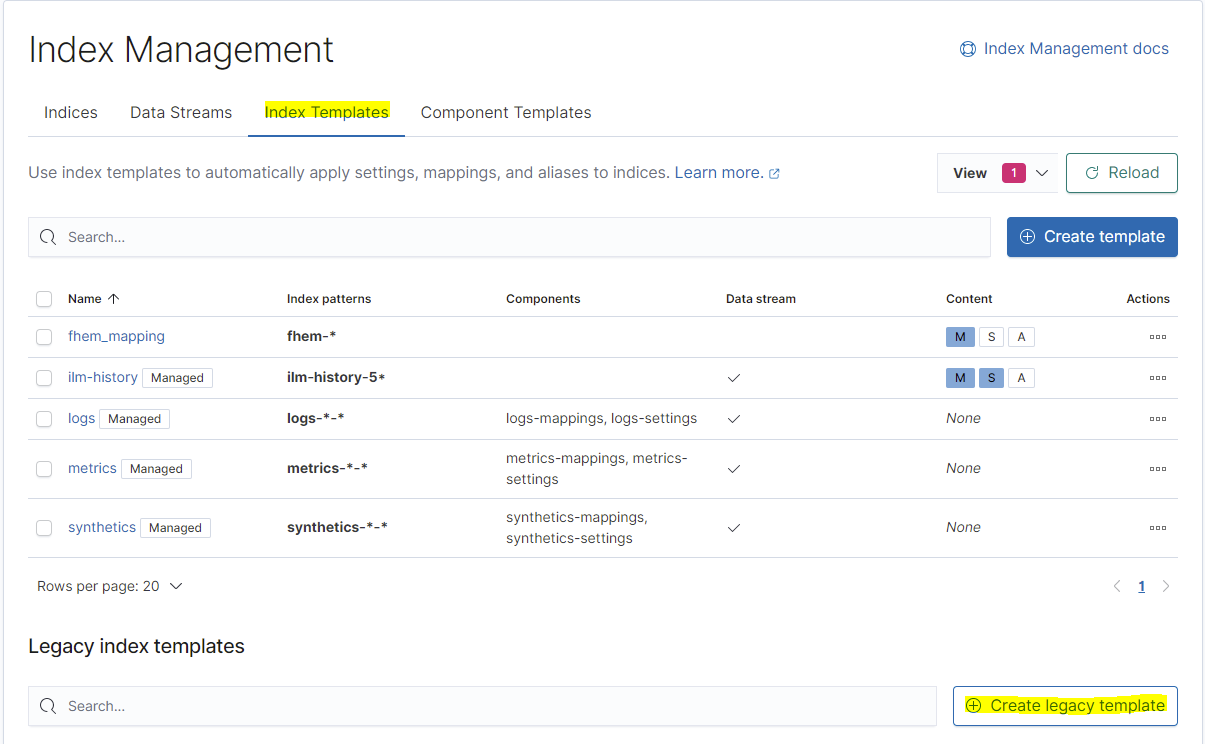
Nun muss für jeden Datentyp eine Vorlage erstellt werden, damit 1. die korrekten Datentypen für jedes Feld im Index eingelesen werden können und 2. auch für jeden Tag ein neuer Index angelegt wird.
Auch dieser Schritt muss nun 5 Mal wiederholt werden, auch hier gibt es nach jedem Screenshot immer wieder REST für die Profis:
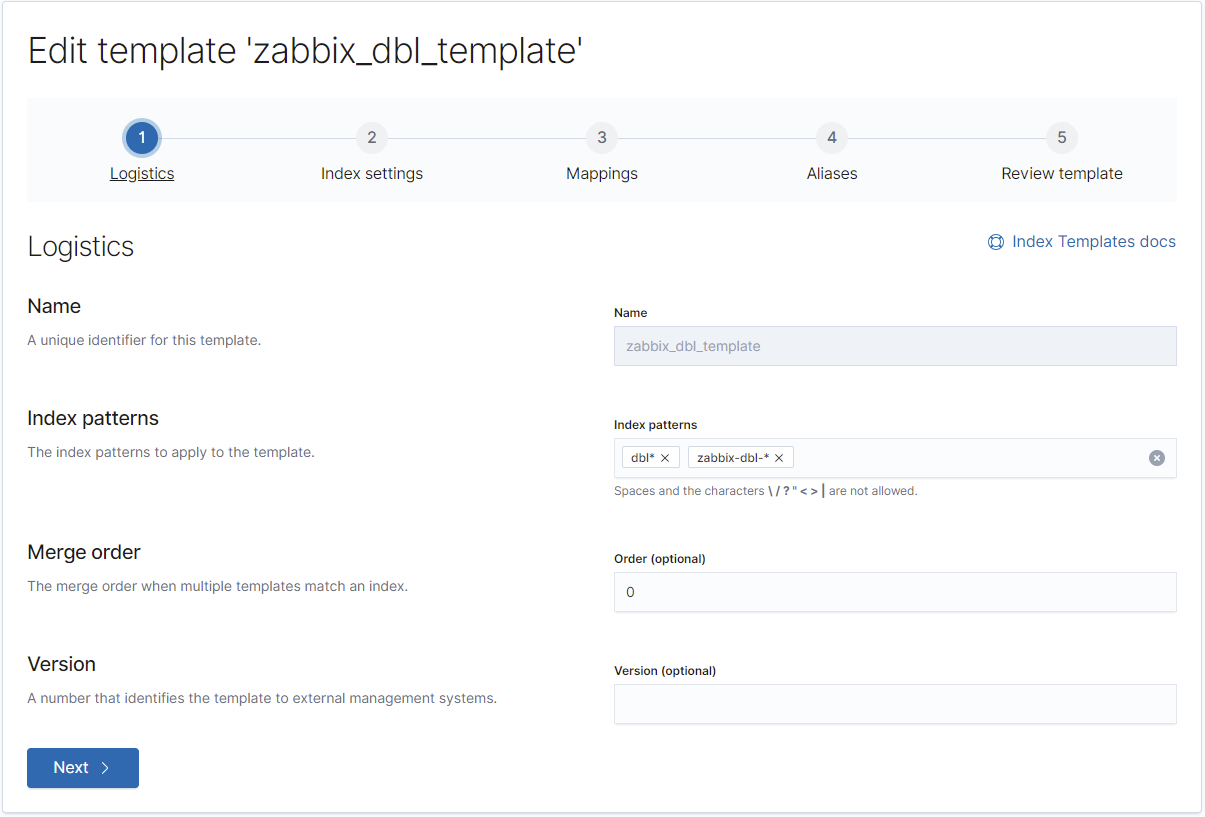
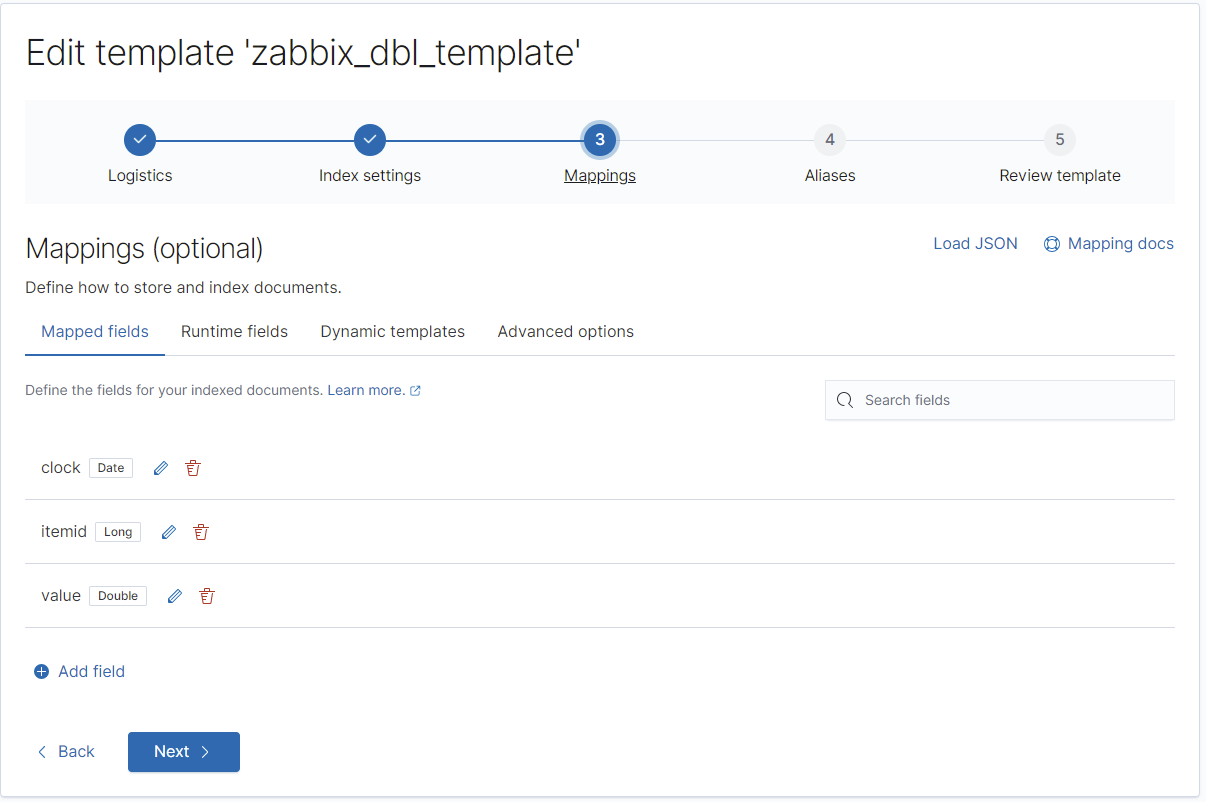
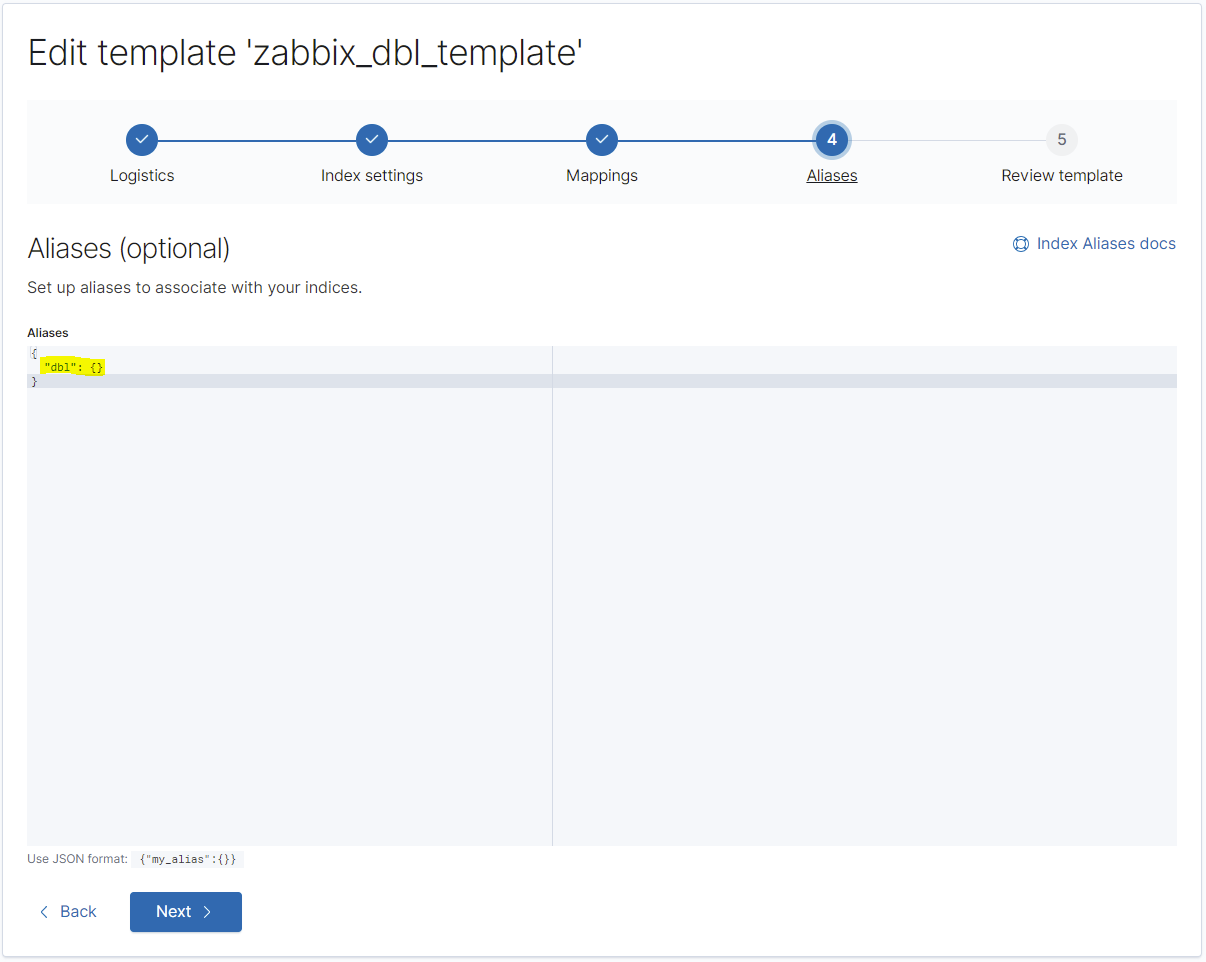
Hier ist es wichtig, den Alias nicht zu vergessen. Zabbix senden jeden Datentyp einfach ohne jeglichen Präfix oder Datumsangabe in die Elasticsearch-Instanz, weshalb wir hiermit Elasticsearch mitteilen, in diesem Fall diese Vorlage zu nutzen.
REST:
PUT _template/zabbix_dbl_template?include_type_name
{
"order": 0,
"index_patterns": [
"dbl*",
"zabbix-dbl-*"
],
"settings": {
"index": {
"number_of_shards": "5",
"number_of_replicas": "1"
}
},
"aliases": {
"dbl": {}
},
"mappings": {
"_doc": {
"properties": {
"clock": {
"format": "epoch_second",
"type": "date"
},
"itemid": {
"type": "long"
},
"value": {
"coerce": true,
"index": true,
"ignore_malformed": false,
"store": false,
"type": "double",
"doc_values": true
}
}
}
}
}Die Vorlagen für die Typen "str", "log" sowie "text" sind wieder langweilig, aber auch hier ist es wichtig, damit Elasticsearch den Timestamp ordentlich in ein Indizierbares Datumsformat umwandeln kann:
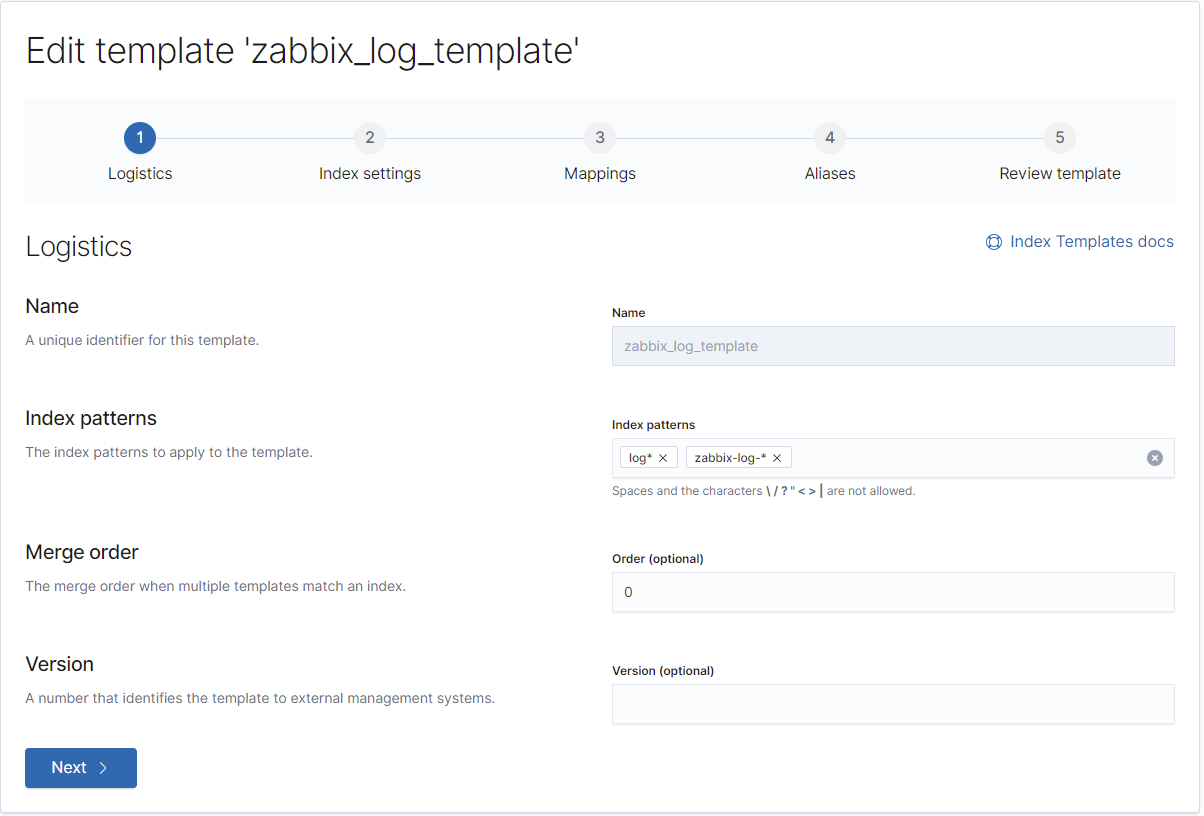
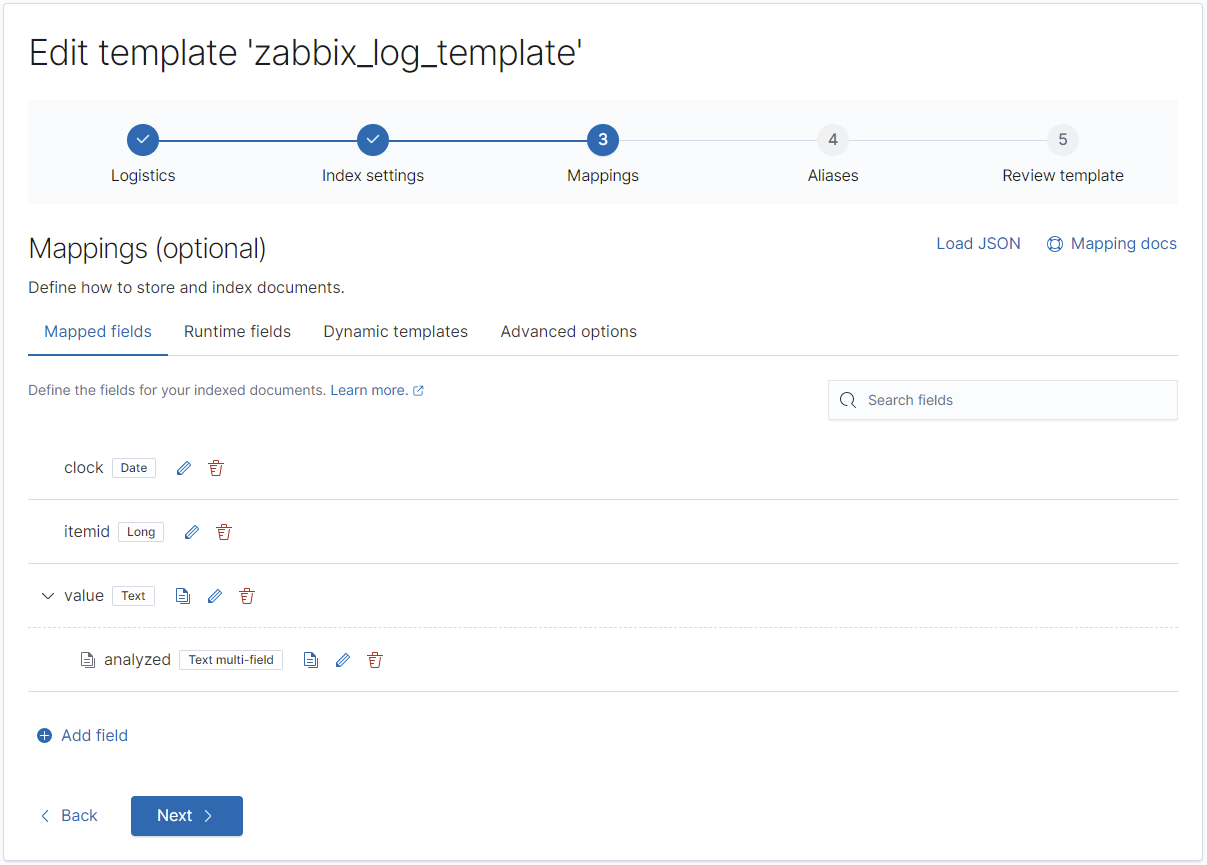
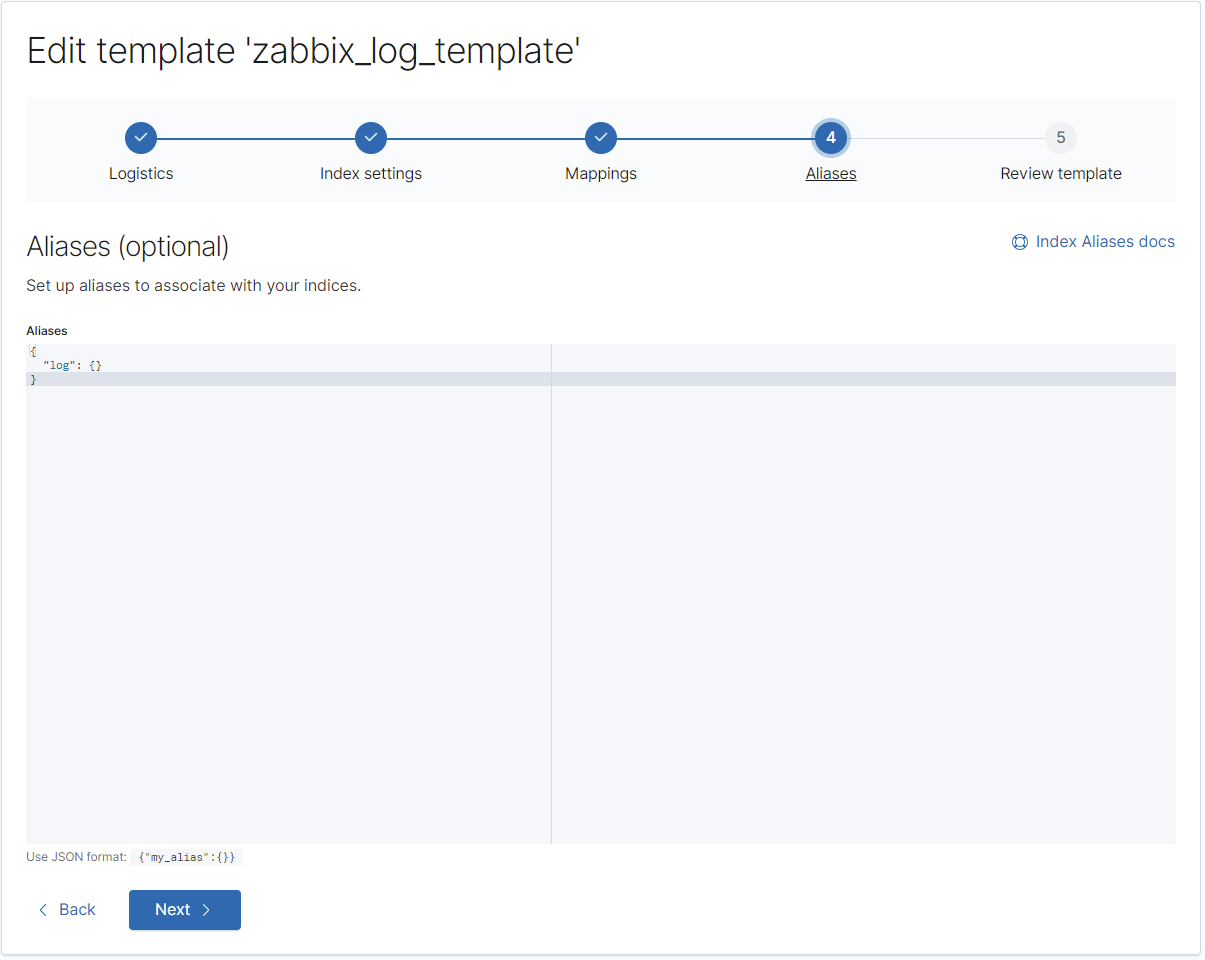
REST:
PUT _template/zabbix_log_template?include_type_name
{
"order": 0,
"index_patterns": [
"log*",
"zabbix-log-*"
],
"settings": {
"index": {
"number_of_shards": "5",
"number_of_replicas": "1"
}
},
"aliases": {
"log": {}
},
"mappings": {
"_doc": {
"properties": {
"itemid": {
"type": "long"
},
"clock": {
"format": "epoch_second",
"type": "date"
},
"value": {
"index": false,
"type": "text",
"fields": {
"analyzed": {
"analyzer": "standard",
"index": true,
"type": "text"
}
}
}
}
}
}
}Vorlage für "str":
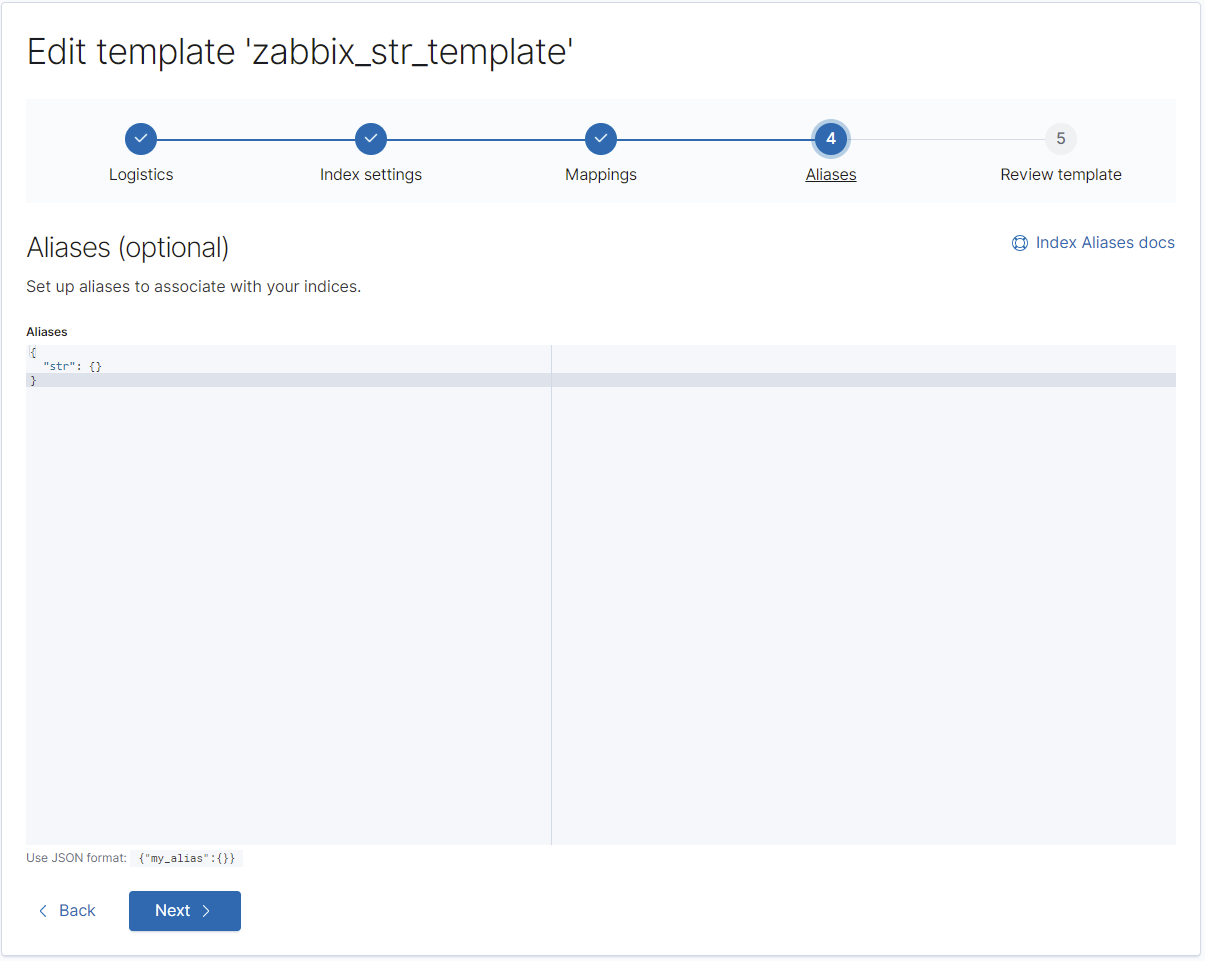
REST:
PUT _template/zabbix_str_template?include_type_name
{
"order": 0,
"index_patterns": [
"str*",
"zabbix-str-*"
],
"settings": {
"index": {
"number_of_shards": "5",
"number_of_replicas": "1"
}
},
"aliases": {
"str": {}
},
"mappings": {
"_doc": {
"properties": {
"clock": {
"format": "epoch_second",
"type": "date"
},
"itemid": {
"type": "long"
},
"value": {
"eager_global_ordinals": false,
"index_phrases": false,
"fielddata": false,
"norms": true,
"index": true,
"store": false,
"type": "text",
"index_options": "positions"
}
}
}
}
}Vorlage für "text":
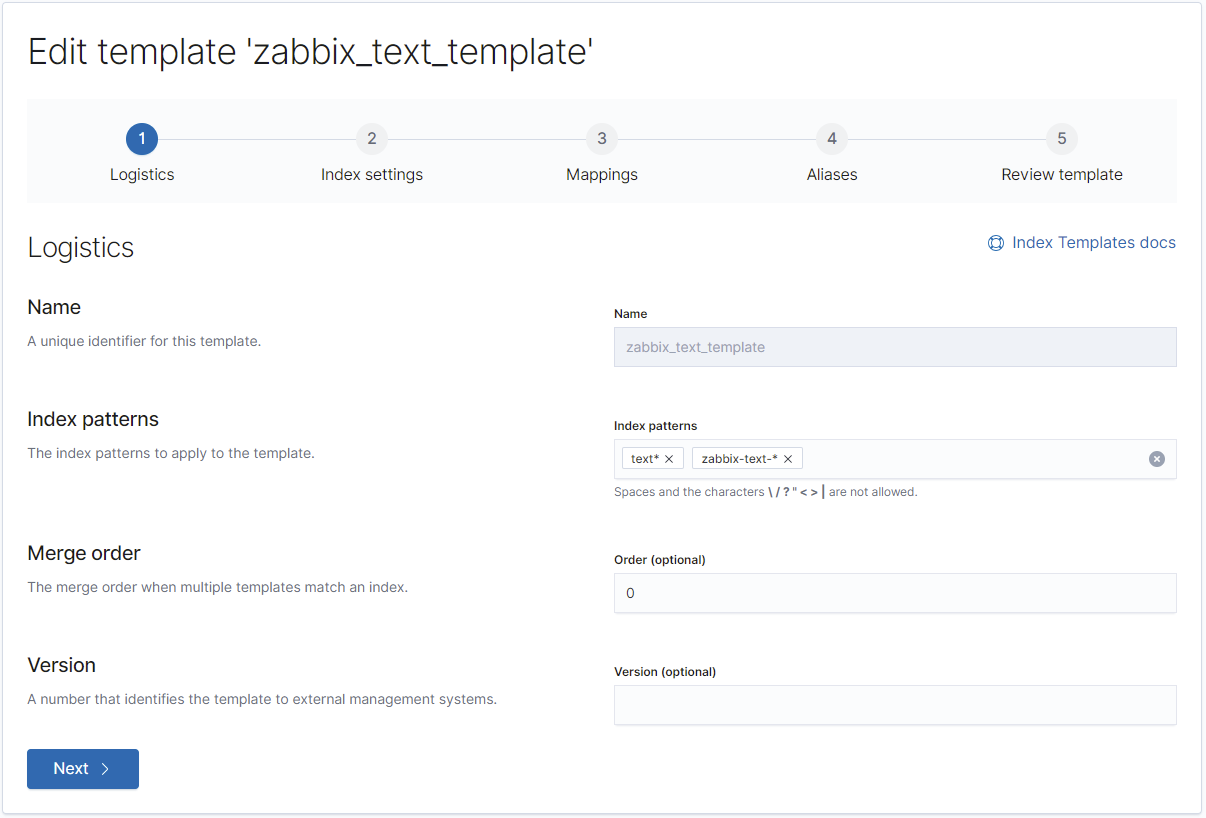
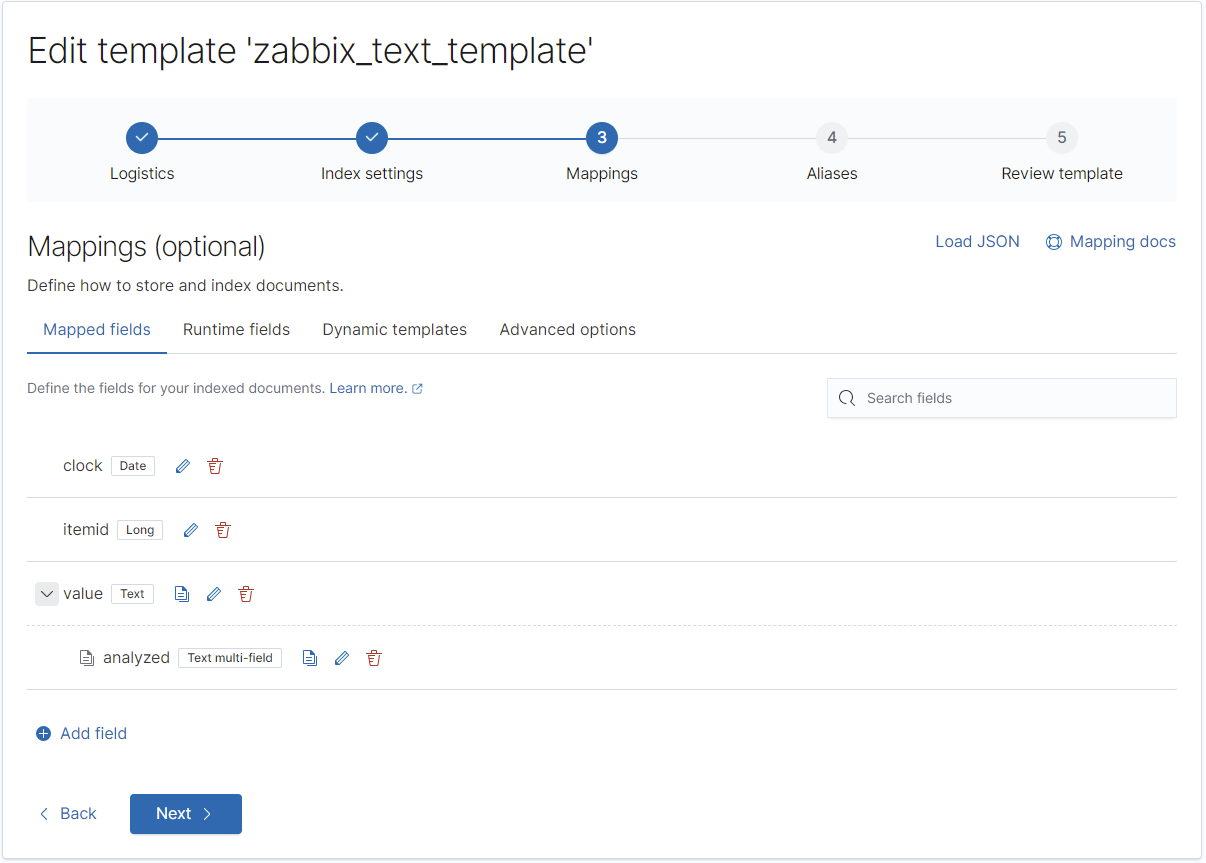
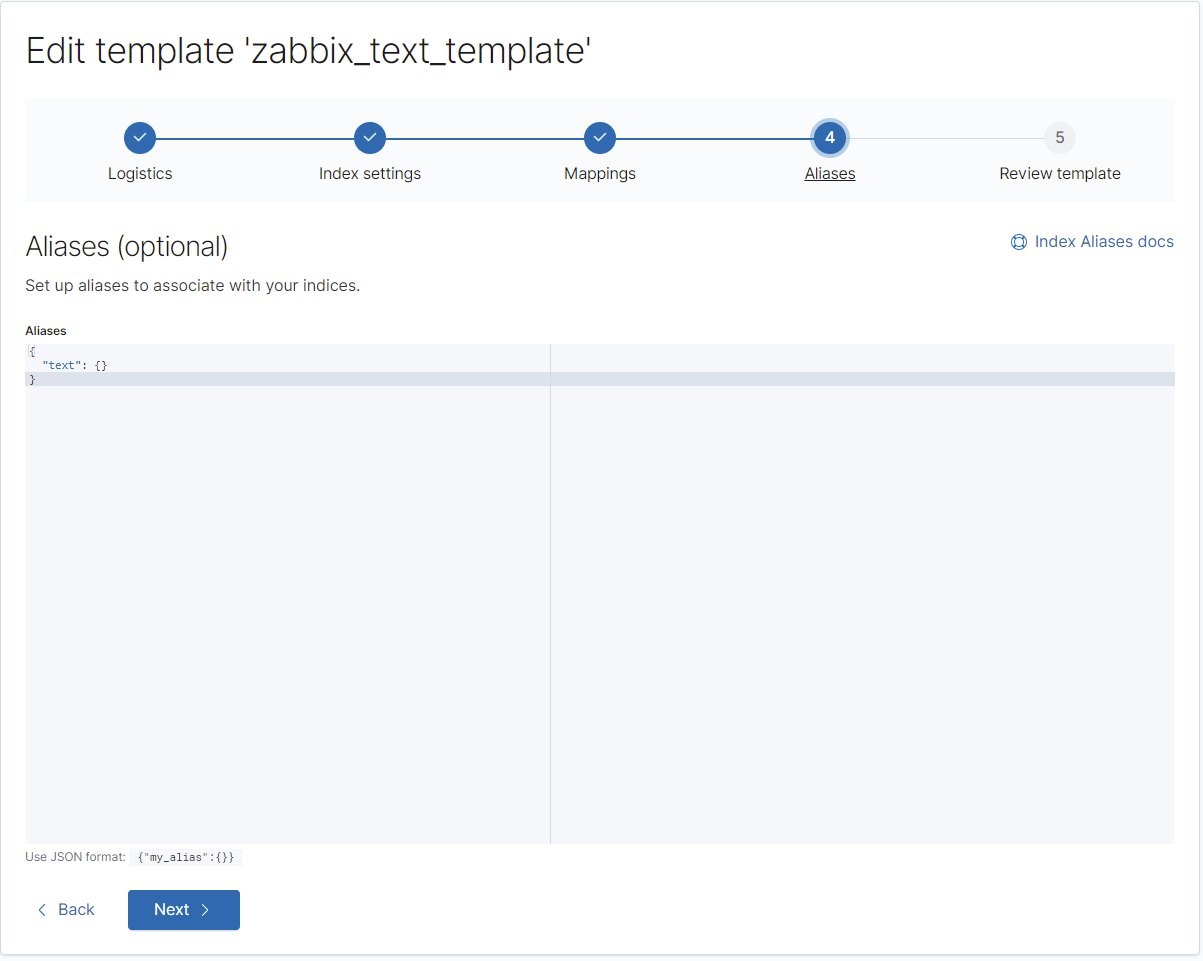
REST:
PUT _template/zabbix_text_template?include_type_name
{
"order": 0,
"index_patterns": [
"text*",
"zabbix-text-*"
],
"settings": {
"index": {
"number_of_shards": "5",
"number_of_replicas": "1"
}
},
"aliases": {
"text": {}
},
"mappings": {
"_doc": {
"properties": {
"clock": {
"format": "epoch_second",
"type": "date"
},
"itemid": {
"type": "long"
},
"value": {
"index": false,
"type": "text",
"fields": {
"analyzed": {
"analyzer": "standard",
"index": true,
"type": "text"
}
}
}
}
}
}
}So, da wir nun die Vorlagen alle erstellt haben, sollten diese nun in der Übersicht alle 5 sichtbar sein:
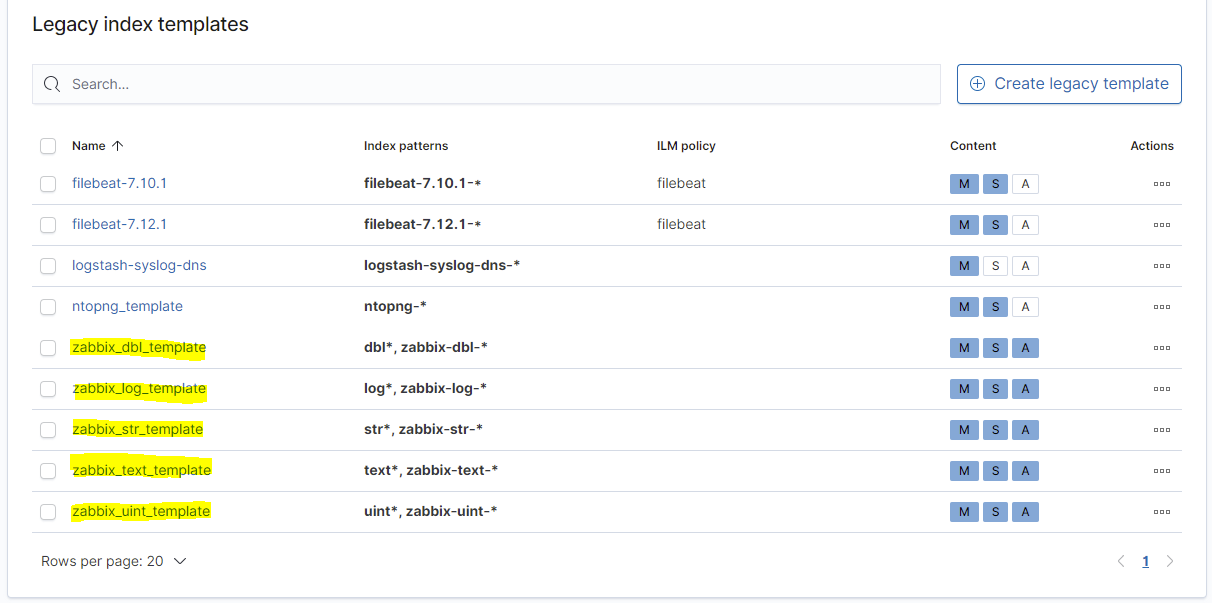
Nun haben wir alle Vorbereitung getroffen, damit Zabbix in Kombination mit Elasticsearch funktioniert.
Wir können nun den Zabbix-Server sowie die Weboberfläche von Zabbix bzw. den Nginx-Server neu starten und die Daten werden in Elasticsearch gespeichert. Wenn der Zabbix-Server neu gestartet wurde, kann nach kurzer Zeit der Import der Daten nach Elasticserarch beobachtet werden.
Damit wird nun in Kibana auch sehen können, welche Daten von Zabbix in Elasticsearch geschoben werden, müssen wir noch für jeden Datentyp jeweils eine "Index Pattern" definieren, welche dann die jeweiligen Indexe zu einer Timeline zusammenführt und in der Kibana GUI durchsuchbar macht. Dazu klicken wir auf der linken Seite im Menü auf "Index Patterns":

Dort klicken wir rechts auf die Schaltfläche "Create index pattern":

Nun fügen wir einen neuen Index hinzu, in diesem Beispiel nehmen wir den Index für den "dbl" Datentyp, also:
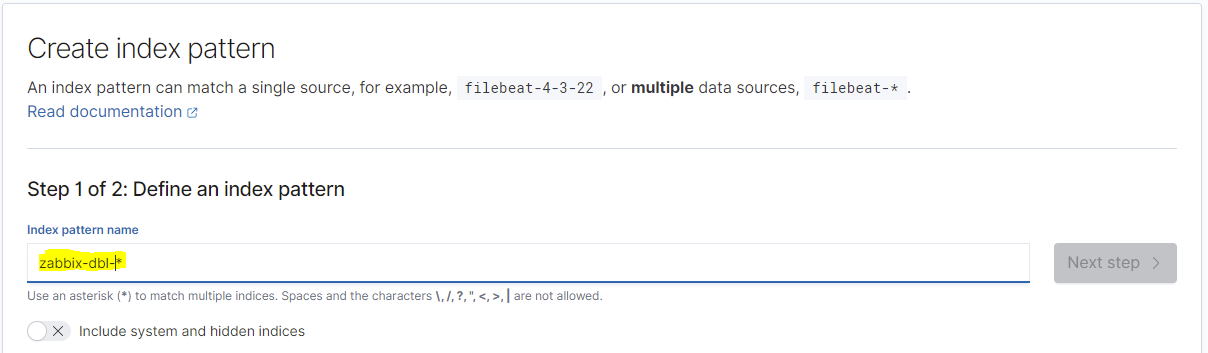
Es werden nun also alle Indexe mit der Zeichenfolge "zabbix-dbl-" in den Index aufgenommen. Sollte im unteren Bereich keine Indexe mit der Zeichenfolge gefunden werden, bitte den Zustand bzw. die Einstellungen des Zabbix-Servers überprüfen. Je nach Datentyp kann es einige Minuten dauern, bis dieser angelegt wird. Ein korrekt angelegter Index wird dann wie folgt angezeigt:
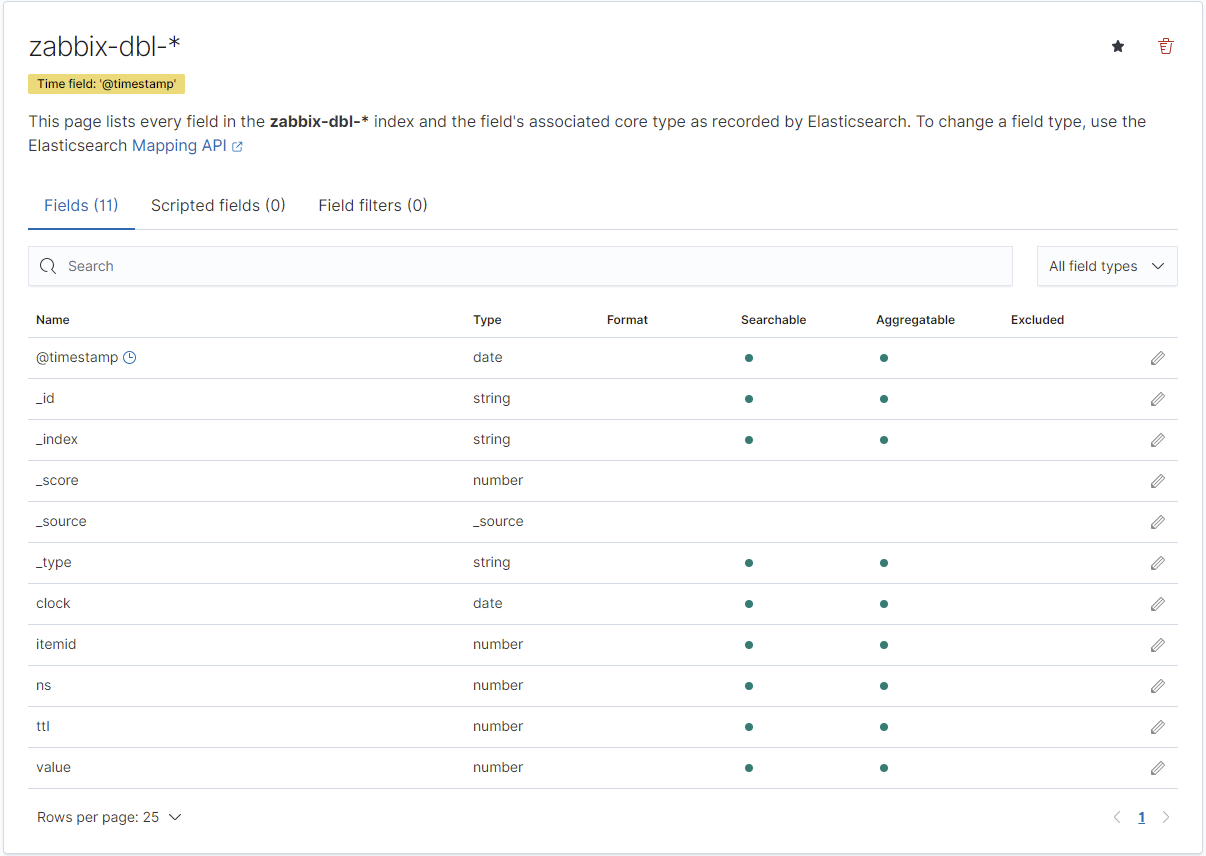
Dieser Vorgang kann nun für alle Datentypen wiederholt werden. Nun sehen wir uns die Rohdaten in Elasticsearch an. Dazu klicken wir oben im Kibana-Menü auf die Schaltfläche mit den 3 Linien und dann im Menü auf "Discover":
Nun müssten nach wenigen Sekunden Daten angezeigt werden. Evtl. muss im Auswahlfeld für den Index noch "zabbix-<Datentyp>-*" ausgewählt werden:
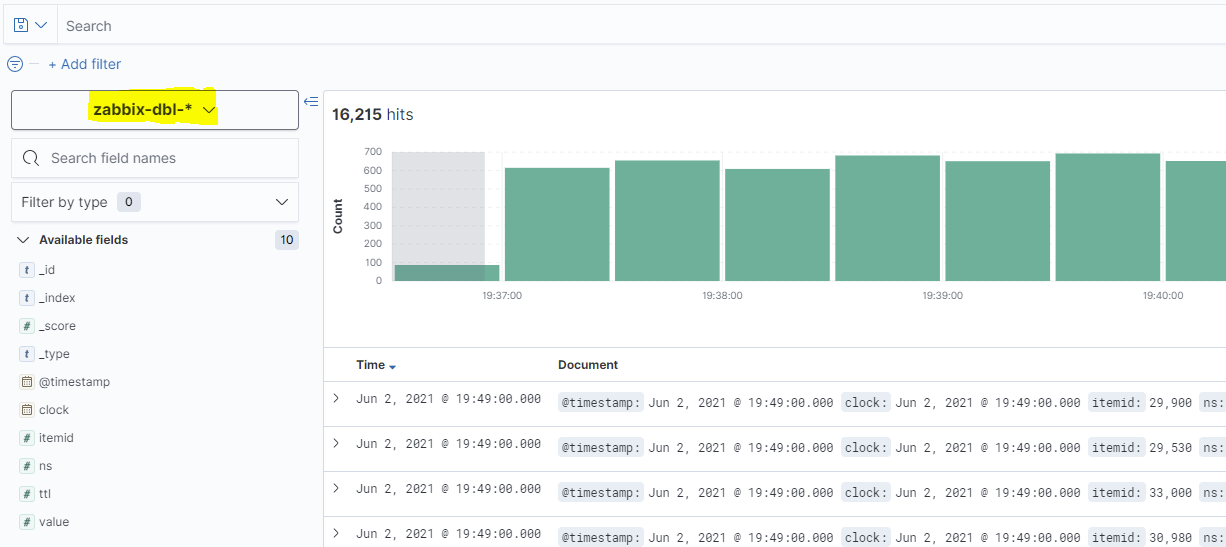
Die Daten an sich kann man leider wenig sinnvoll in Kibana auswerten, da Zabbix mit dem Feld "itemid" intern die Zuordnung für den Host sowie für das jeweilige Item in Zabbix führt. Theoretisch wäre es möglich einen Export aus der SQL-Datenbank zu machen und damit die Werte zuordnen zu können, aber Zabbix bringt hierfür ja bereits Möglichkeiten mit...
Da nun die Daten nur noch in Elasticsearch gespeichert werden, ist die SQL-Datenbank nun sehr viel entspannter und hier werden nur noch die Informationen der Hosts sowie der Trigger von Zabbix gespeichert. Ab dem Zeitpunkt des Server-Neustarts von Zabbix beginnt die Historie von allen Hosts nun wieder von Anfang an, d.h. die Altdaten der SQL-Datenbank können nun nicht mehr durch das Webinterface ausgelesen werden. Theoretisch könnten die Tabellen in der SQL-Datenbank geleert werden um die Größe der SQL-Datenbank zu optimieren.
Es wird empfohlen, nun ein Backup über die Backup & Restore-Funktion von Elasticsearch einzurichten, damit hier keine Daten verloren gehen können. Je nach Intervall der Datenwerte können am Tag mehrere 100MB Indexdaten anfallen. Hier sollte sich auch über eine "Index Lifesycle Policy" Gedanken gemacht werden, denn Zabbix löscht keinerlei Daten aus Elasticsearch. Elasticsearch wird alle Indexdaten in der Standardeinstellung unbegrenzt (also bis auf dem Host kein Speicher mehr frei ist) speichern. Hier wäre es z.B. auch möglich mit einer "Cold node" Daten älter als 30 Tage auf eine Elastic-Node mit langsamerem Speicher zu verschieben, um diese Daten dann zwar noch abrufen zu können, aber diese nicht dauerhaft auf einer Node vorhalten zu müssen.